L’automate utilisé dans la suite de cette formation est l’automate Siemens S7-1200.
3.1 Configuration LINA
3.1.1 LINA Services & Surveillance
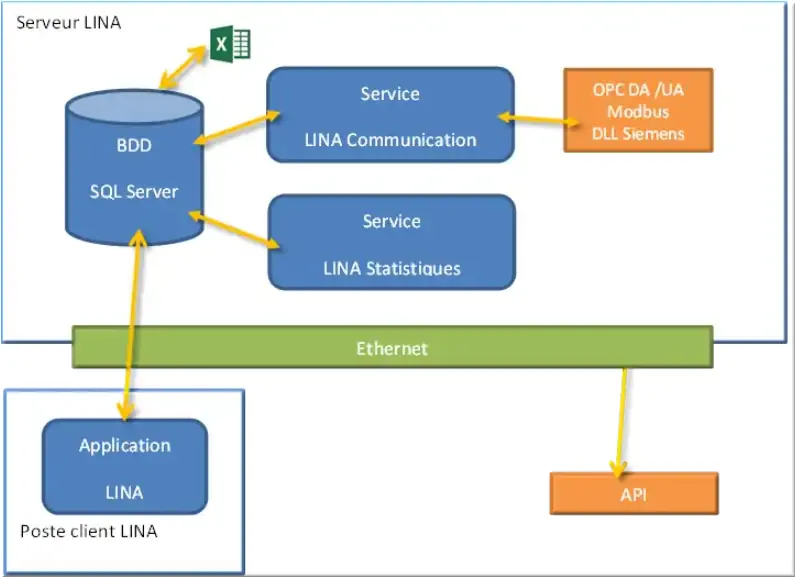
Figure 6 : Architecture en local de LINA
LINA possède deux services majeurs qui caractérisent son fonctionnement :
- LINA Service Statistiques, qui exécute les traitements sur la base de données pour l’affichage dynamique des fonctions de bases de LINA, l’envoi d’email, de SMS, purges des historiques LINA, export Excel ;
- LINA Service Communication, qui permet l’établissement et le maintien de la communication avec l’ensemble des devices communiquant avec LINA.
La surveillance des applications présente un double intérêt : pouvoir générer une alarme en cas de service défaillant et permette la configuration des services. Pour des raisons de performance, il est possible de configurer les services sur des machines distantes.
Dans notre projet, l’ensemble des services sera exécuté en local, sur le PC portable PORT2312-004.
Tous les services sont connectés à la base de données SQL.
Dans LINA Energies :

Figure 7 : Menu principal
- Clic Menu principal.
Ce tutoriel est structuré par le mode opératoire suivant indiquant qu'il faut changer de fonctionnalités dans le logiciel LINA. Dans la suite de ce tutoriel, ce clic au Menu principal ne sera plus mentionné avant "Accéder à ".
Dans Menu principal :

Figure 8 : Accès Surveillance des applications
- Accéder à Configuration > Configuration > Surveillance des applications.
À gauche, le bouton ☸ Configuration de couleur bleu foncé est dans la barre d'outils de navigation ↕ verticale.
⚠ Attention : la barre horizontale ↔ d'outils – dans ce 1er exemple de même nom Configuration -- en bleu plus clair peut ne pas être alignée comme le présente le résumé de capture d'écran.
Dans la matrice des menus, scroller verticalement ou chercher tout en haut au niveau de "Menu complet". Voir Tutoriel Baptême Lina > 1. Parcourir Lina Pro > 1.4 Gestion des menus.
Dans Surveillance des applications :
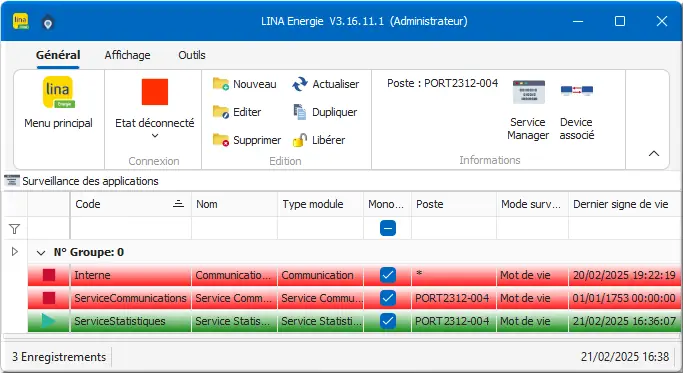
Figure 9 : Liste des Services
Vérifier la liste des applications déclarées :
- Il est impératif d’avoir Service Communications et Service Statistiques.
Si chacun de ces Services n'est pas déclaré, commencer par ajouter Service Statistiques.
Dans LINA Energies > Configuration > Surveillance des applications :
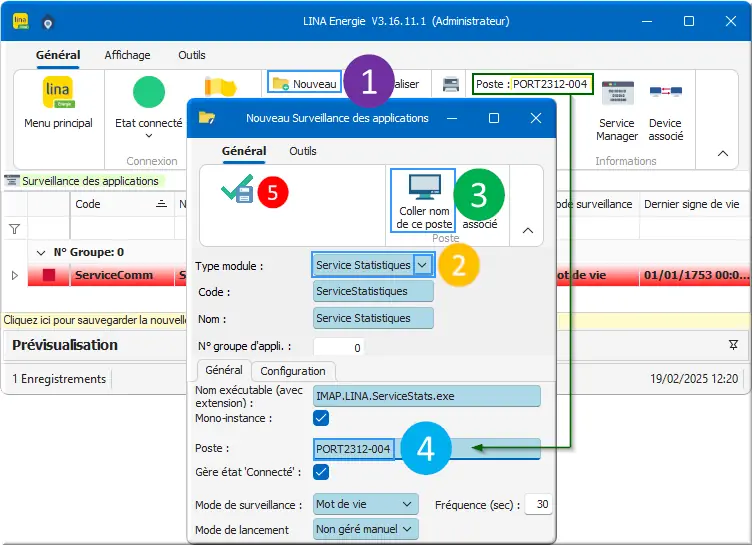
Figure 10 : Ajout de Statistiques
- Clic Nouveau.Le bouton Nouveau est contextuel à la fenêtre courante "Surveillance des applications" ;
- Type module : Service Statistiques.Choisir dans le menu déroulant ⟏ le module Service Statistiques différent de
Status; - Clic Coller nom de ce poste ;
- Vérifier que ce nom de PC est le même que Poste : PORT2312-004 dans le bandeau ;
- Clic ✓ Enregistrer Fermer.
Par la suite, un menu déroulant sera simplifié en listbox avec l'icône ⟏ plutôt que la lettre "v" ou " ⌄".
Idem pour ServiceComm :
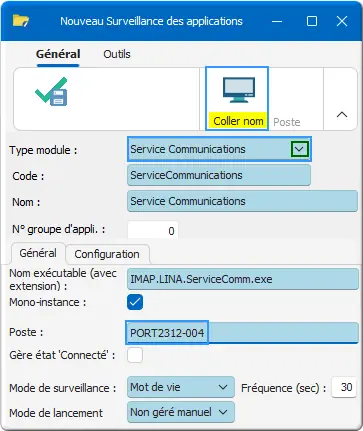
Figure 11 : Ajout de Service Communications
Type module : Service Communications.Poste : PORT2312-004.
Si les services étaient déjà déclarés :
- Sélectionner chacun à leur tour les deux services. Clic Éditer au lieu de Nouveau ;
- Clic Coller nom de ce poste pour chacun des services ;
- Clic ✓ Enregistrer Fermer.
3.1.2 Création serveur et device
Tout appareil connecté avec LINA doit être associé à un serveur de communication. Dans notre projet convoyeur, le type de communication S7 de Siemens est utilisé et assuré en direct par LINA. Pour d’autres types d’automates la communication peut se faire par l’intermédiaire par exemple d’un serveur de communication OPC DA. D’où la nécessité de déclarer un serveur, puis le rattachement d’un appareil
Accéder à Référentiel > Device/Mnémonique > Serveurs :

Figure 12 : Accès à la liste des serveurs
Dans Liste des serveurs :
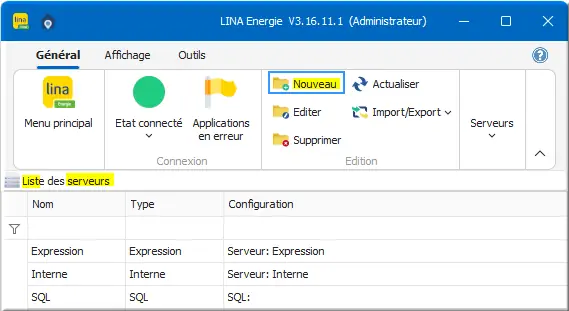
Figure 13 : btn Nouveau serveur
- Clic Nouveau pour créer le serveur SIEMENS.
Dans Nouveau Serveurs :
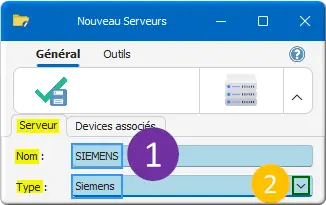
Figure 14 : nouveau serveur SIEMENS
- Nom : SIEMENS en MAJUSCULE est le serveur.
Type : Siemens en Sentence case est le Type de communication ; - Clic ✓ Enregistrer Fermer.
Accéder à Référentiel > Device/Mnémonique > Device et surveillance :

Figure 15 : Accès Device et surveillance
Dans Liste des devices et surveillance :
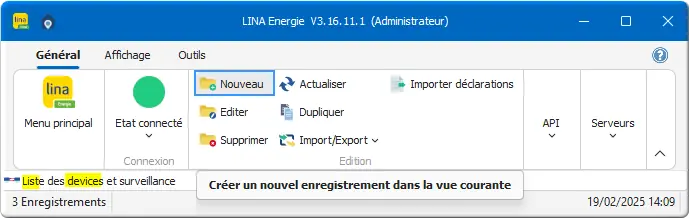
Figure 16 : btn Nouveau Device
- Clic Nouveau pour créer notre Device : API_CONVOYEUR.
Dans Nouveau Device et surveillance, onglet Général :
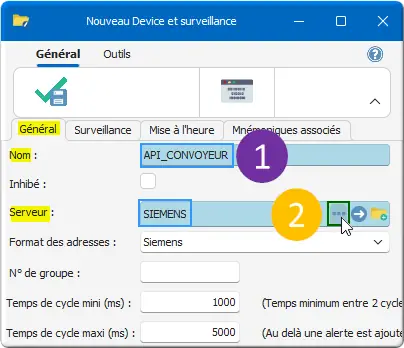
Figure 17 : nouveau Device API_CONVOYEUR
- Nom : API_CONVOYEUR ;
- Server : SIEMENS.
Le choix du nom du device est libre mais doit rester cohérent dans le projet. On prendra ici API_CONVOYEUR.
Rappel : Dans LINA, les champs en bleu sont obligatoires à la saisie.
Dans Serveurs :
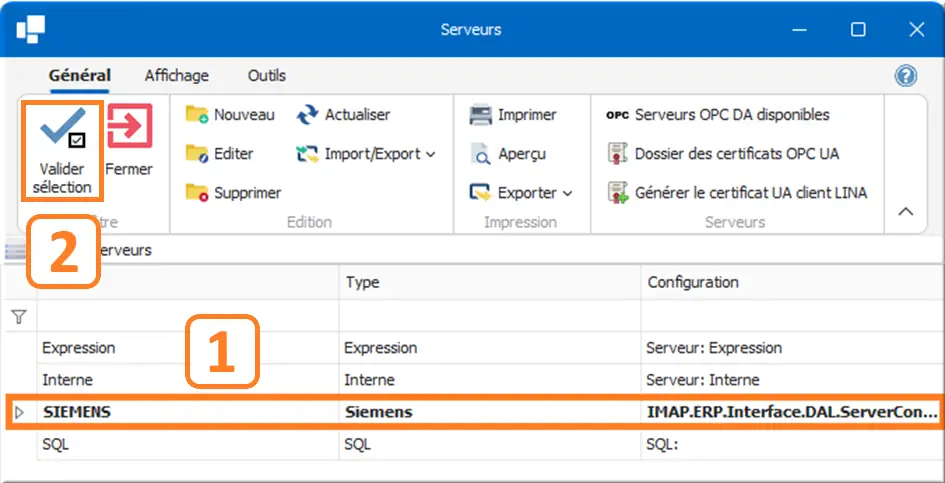
Figure 18 : Rattachement du serveur au device
- Ligne SIEMENS, colonne Configuration : clic "…" > IMAP.ERP.Interface.DAL.ServerConfigBase
Pour le choix du serveur, rattacher le device au serveur SIEMENS créé précédemment dans le menu qui s’ouvre après le clic sur "…" ; - Clic ✓ Valider sélection.
Retour sur la 1ère fenêtre, pour finaliser la création du device.
Dans Editer Device et surveillance, onglet Général :
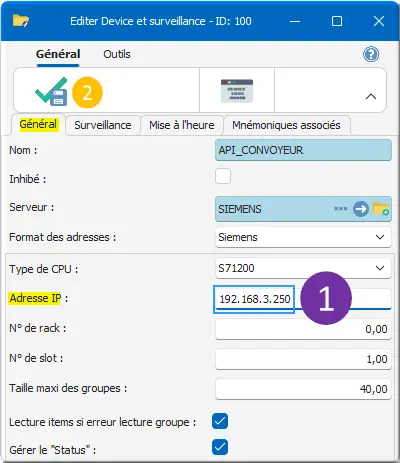
Figure 19 : Suite configuration du Device
Type de CPU : S7-1200 déjà par défaut. Il s’agit du modèle d’automate dans notre projet Siemens
- Adresse IP : 192.168.3.250 définie dans l’automate SIEMENS pour notre projet ;
- Clic ✓ Enregistrer Fermer.
Informations complémentaires :
N° de groupe : permet de créer des groupes de Devices. Les devices avec le même N° de groupe sont traités comme un seul par la communication, celle-ci va lire les devices en série au sein de groupe. Cela permet dans le cas de plusieurs devices derrière une passerelle de ne pas la saturer.
Temps de cycle mini (ms) : par défaut 1000 ms, c’est la valeur de temps minimum pour démarrer un cycle de communication dans LINA avec le device. Il n’y a pas de temps maximum, le service LINA Communication peut terminer son cycle après cette valeur théorique. Si le temps de communication est supérieur à ce paramètre, un nouveau cycle recommence sans délais.
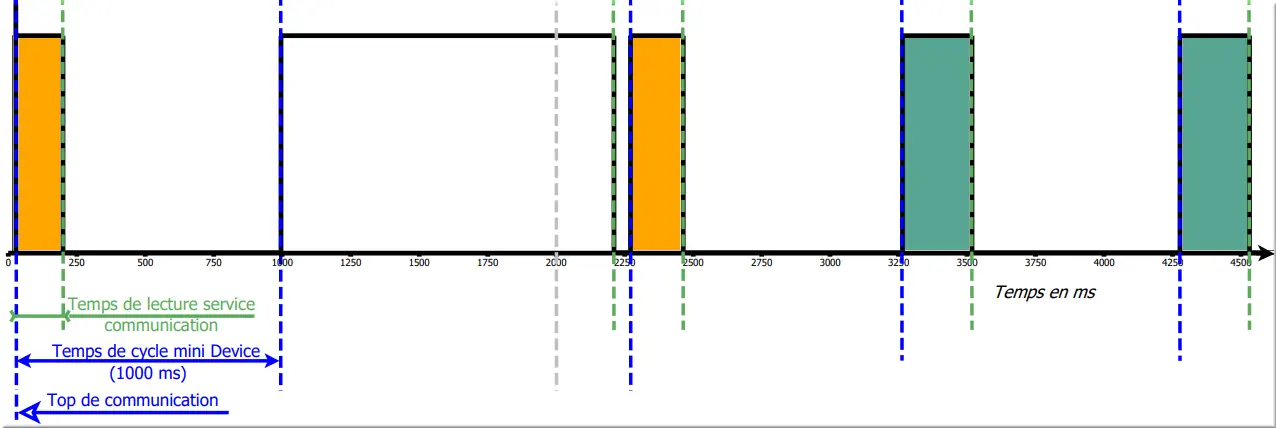
Figure 20 : Chronogramme temps de cycle
Le temps de cycle réel avec le device est visible dans les logs du service LINA Communication : voir chapitre LINA Service Communication.
N° Rack : par défaut 0, emplacement de la CPU
Taille maxi des groupes : Cette valeur précise le nombre de mots lus sur le device par LINA en une requête
Lecture items si erreur lecture groupe : ☑ si l'option est activée, en cas d'erreur de lecture d'un groupe, relit chaque item séparément. Cela peut ralentir les lectures.
Gérer le "Status" : ☑ si l'option est cochée, LINA surveille de façon régulière toutes les minutes que le device réponde bien en consultant l’état good ou bad d’un mnémonique. Le mnémonique vérifié est soit un mnémonique spécifique au status si le device gère, soit un mnémonique aléatoire dans le cas contraire. Si le status est mauvais, les lectures sont suspendues jusqu'à ce que le status redevienne bon.
3.1.3 Déclaration mnémonique
Prérequis : 5. Adressage | Formation - TIA PORTAL
La déclaration d’un mnémonique permet l’utilisation des données de l’automate pour leur exploitation dans LINA. Voici un exemple des mnémoniques à importer manuellement :
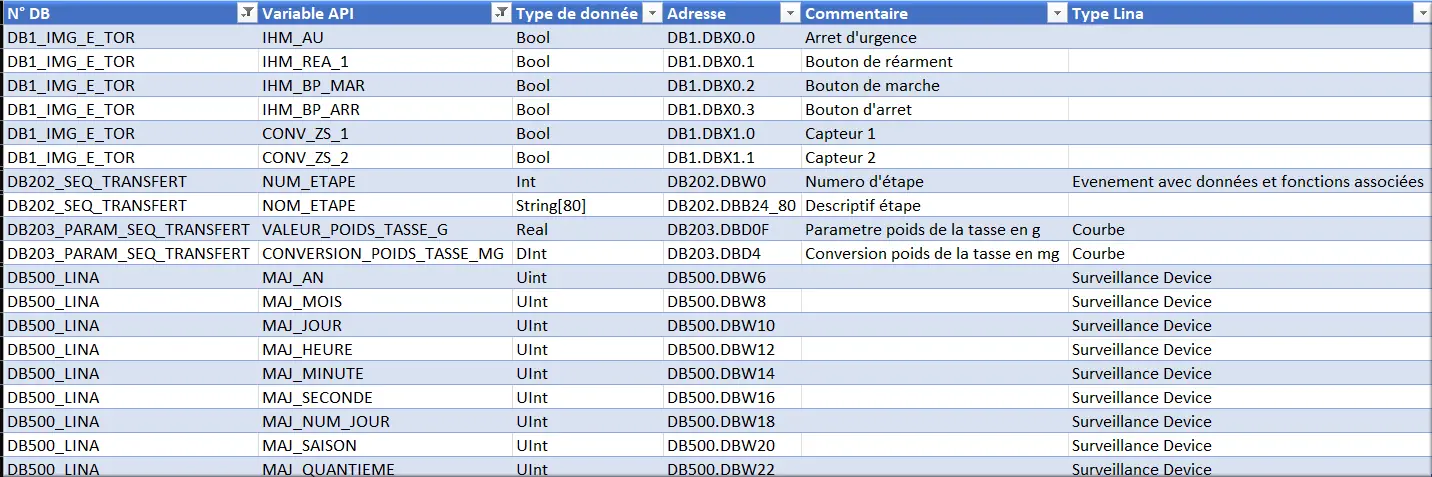
Figure 21 : Exemple liste mnémo à importer
D’un point de vue automatisme, DB signifie Data Block et permet la sauvegarde des données dans la CPU de l’automate. Le format de l’adresse diffère avec le type de la donnée :
- Bool = DB*.DBX*.* Valeur binaire 0 ou 1, taille 1 bit ;
- Int = DB*.DBW* Valeur entière signée, taille 16 bits ;
- DInt = DB*.DBD* Valeur double entière signée, taille 32 bits ;
- UInt= DB*.DBW* Valeur entière non signée, taille 16 bits ;
- Real = DB*.DBD*F Valeur avec virgule, taille 32 bits ;
- String [40] =DB*.DBB*_Taille Chaîne de caractère, taille 8 x 40 bits.
Siemens utilise en début de chaîne le premier octet pour définir la chaîne et le deuxième octet pour le nombre de caractère contenu dans la chaîne, il faut donc déclarer le mnémonique avec un décalage de deux octets : DB200.DBB14_40 → DB200.DBB16_40.
Accéder à Référentiel > Device/Mnémonique > Mnémonique :

Figure 22 : Accès Mnémonique
- Clic Nouveau pour générer un nouveau mnémonique manuellement.
Rappel : dans LINA, tous les champs :
- Bleus sont obligatoires à renseigner pour l’enregistrement ;
- Jaunes sont générés automatiquement.
Créer manuellement tous les mnémoniques ci-dessous : un de chaque type.
Dans Editer Mnémonique :
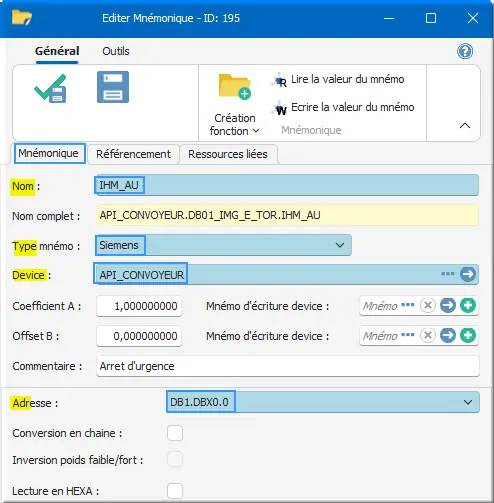
Figure 23 : Déclarer mnémo IHM_AU
- Nom : IHM_AU toujours utiliser l’intitulé utilisé dans l’automate pour maintenir une facilité de compréhension avec l’automaticien, ainsi qu’une rapidité en maintenance ;
- Type mnémo : Siemens ;
- Device : API_CONVOYEUR fournisseur du mnémonique ;
- Commentaire : Arret d'urgence. La zone commentaire reste libre pour apporter des précisions quant à l’objectif du mnémonique
- Adresse : DB1.DBX0.0
Une liste des mnémoniques disponibles doit être fournie par l’automaticien. Vous pouvez présélectionner l’adresse dans la liste et remplacer le joker "*" par des chiffres, exemple :
Pour un bool générique :

Figure 24 : Adresse prédéfinie d’un booléen
Avec des nombres, l’adresse devient :

Figure 25 : Adresse modifiée d’un booléen
Pour l'INT entier NUM_ETAPE :
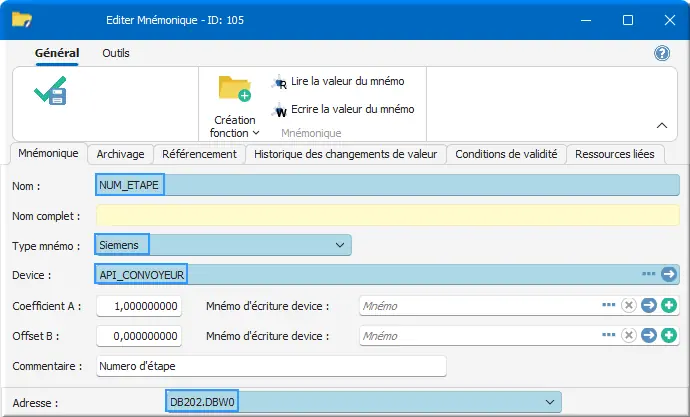
Figure 26 : Déclarer mnémo NUM_ETAPE INT
Pour le DINT double ENTIER CONVERSION_POIDS_TASSE_MG :
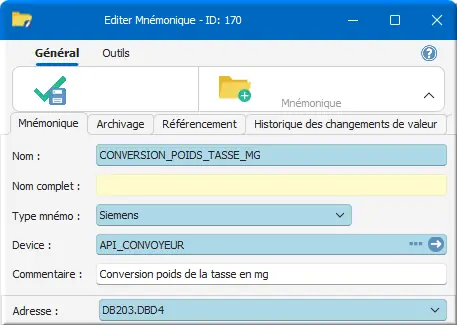
Figure 27 : mnémo CONVERSION_POIDS_TASSE_MG DINT
Commentaire : Conversion poids de la tasse en mg.
Pour l'UINT entier non-signé MAJ_AN :
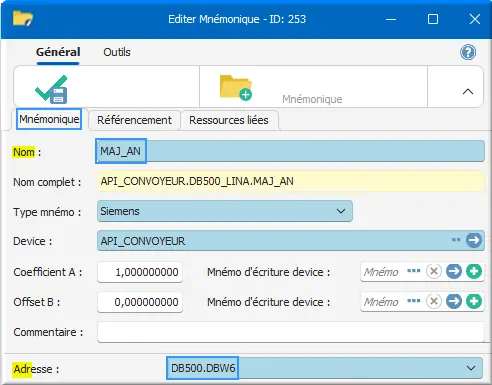
Figure 28 : mnémo MAJ_AN UINT
Pour le RÉEL VALEUR_POIDS_TASSE_G RÉEL :
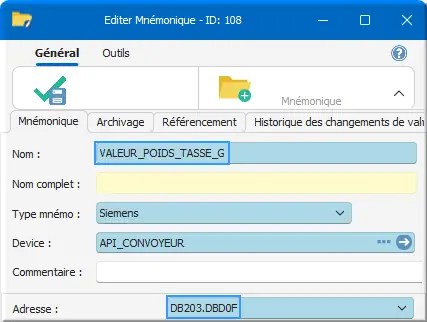
Figure 29 : mnémo VALEUR_POIDS_TASSE_G réel
Pour la STRING NOM_ETAPE : chaîne de caractères.
Il faut déclarer le mnémonique comme un INT et cocher Lecture en tableau.
⚠ Attention : Ne pas oublier le décalage sur l’adresse !
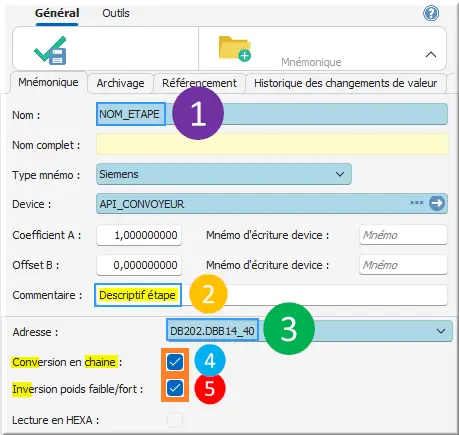
Figure 30 : mnémo NOM_ETAPE string
- Nom : NOM_ETAPE ;
- Commentaire : Descriptif étape ;
- Adresse : DB202.DBB14_40 ;
- Conversion en chaine : ☑ ;
- Inversion poids faible/fort : ☑.En cas de problème de remontée incohérente sur la chaîne de caractère, il est possible d’inverser la lecture des bits de poids fort et faible.
- Une fois les mnémoniques susmentionnés déclarés, on obtient le résultat suivant dans la liste des mnémoniques :

Figure 31 : Résultat déclaration manuelle mnémo
3.1.4 Arborescence des mnémoniques
Les mnémoniques ont une arborescence propre, différente des arborescences physiques et thématiques.L’arborescence se construit en fonction des devices ou des sources de provenance du mnémonique. Ainsi, nous retrouvons par défaut d’autres sous-dossiers :
- SQL : correspond à un mnémonique basé sur une requête SQL en Lecture seule ;
- Interne : correspond à un mnémonique interne à LINA et modifiable uniquement via LINA.
Nous allons créer une arborescence mnémonique lié à notre device en faisant clic droit sur le dossier Racine :
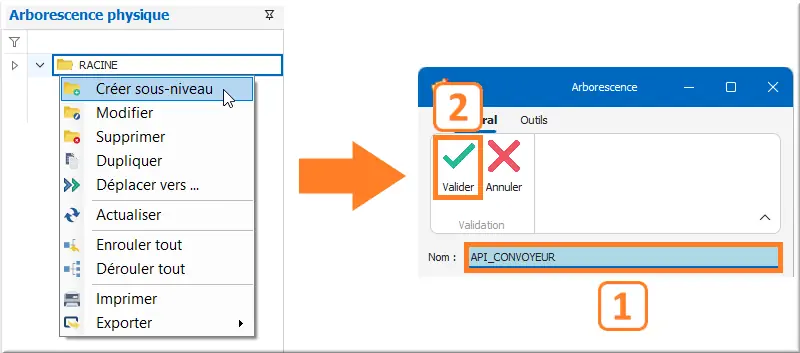
Figure 32 : Arbo Racine API_CONVOYEUR
- Créer un sous-niveau, et nommer ce sous-niveau API_CONVOYEUR ;
- Clic ✓ Valider.
Vous pouvez ensuite ranger les mnémoniques déjà créés dans RACINE dans le sous-dossier API_CONVOYEUR par un glisser-déposer.
Nb : Il est possible de sélectionner plusieurs lignes en même temps à l’aide des touches du clavier :
- Ctrl+Clic, sélection une par une ;
- Shift+Clic, sélection de l’ensemble des listes entre la sélection en cours et finale ;
- Ctrl+Shift+Clic, sélection de plusieurs ensembles un par un ;
- Ctrl+A pour sélectionner l’ensemble de la liste.

Figure 33 : Liste mnémo déclaré
Nos 6 mnémoniques sont maintenant dans le dossier API_CONVOYEUR. Cependant, comme pour les noms de ces mnémoniques, il est important de respecter l’architecture de l’automate, toujours dans l’optique de faciliter les échanges avec les intervenants en automatisme.
Créer et nommer des sous-dossiers à API_CONVOYEUR avec les N° de DB automate : revoir tableau début de chapitre. Obtenir l’arborescence suivante :
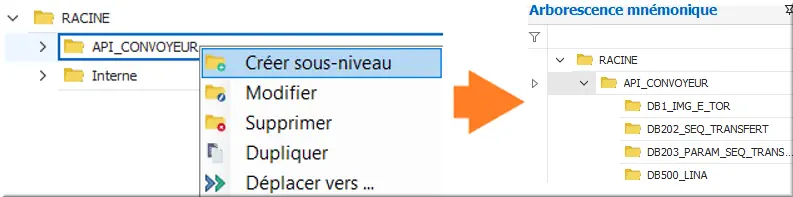
Figure 34 : Arborescence mnémonique complète
Déplacer ensuite les mnémoniques créés dans les arborescences DB correspondantes.
En sélectionnant API_CONVOYEUR, vous observerez l’ensemble des mnémoniques liées à notre device.
En sélectionnant un des sous-dossier DB* créés, uniquement les mnémoniques présents dans le sous-dossier DB s’affichent :
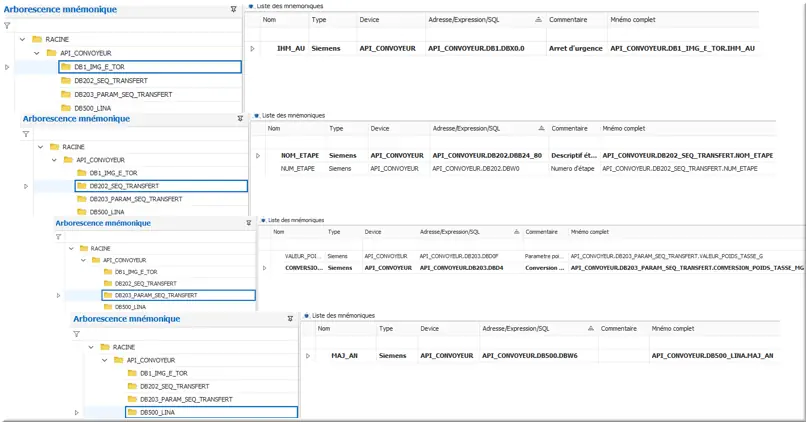
Figure 35 : Contenus des sous-dossiers
Pour obtenir le chemin d’accès des mnémoniques, consulter la dernière colonne Mnémo complet à droite.
3.1.5 Import mnémonique
Pour une déclaration plus simple et rapide des mnémoniques, il est possible de faire une intégration d’un fichier extrait de l’automate au format CSV : fichier texte avec séparateur de champs.
Le fichier Excel ListVarConvMod_N1_VXX fourni avec le projet est le suivant :
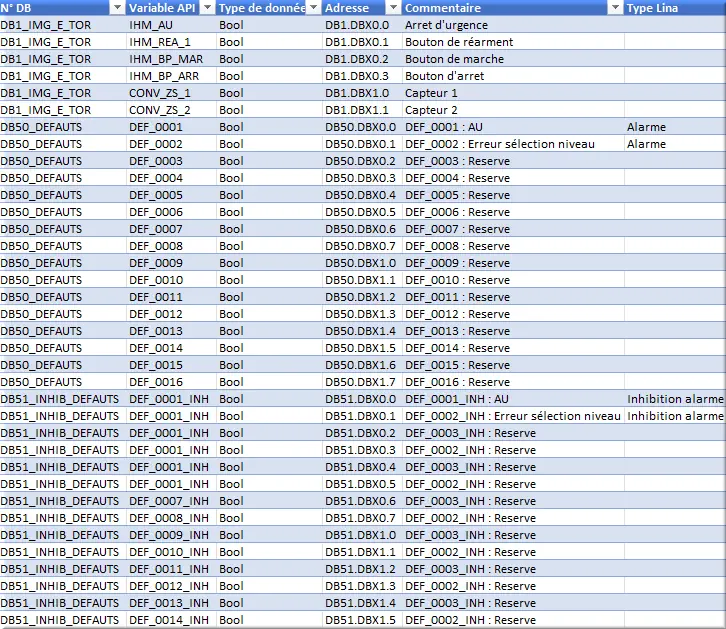
Figure 36 : Exemple fichier mnémonique via Excel
La déclaration manuelle est toujours valable, l’import étant capable de gérer les potentiels conflits avec les mnémoniques déjà existants.
Avant d’utiliser l’import de LINA, il est nécessaire de travailler le fichier Excel pour le rendre compatible :
- Ajout d’une colonne Type de fonction, champ obligatoire pour l’importation. Pour tous les mnémoniques, le type sera MN_SIEM ;
- Ajout d’une colonne Device, qui caractérisera le device concerné dans LINA pour tous les mnémoniques. Pour tous les mnémoniques, le device sera API_CONVOYEUR ;
- Ajout d’une colonne pour correspondance avec l’arborescence physique. Dans notre projet, nous avons ajouté à RACINE le sous-dossier API_CONVOYEUR en première arborescence et le numéro de DB en seconde arborescence.
Pour la conversion en CSV dans Excel :
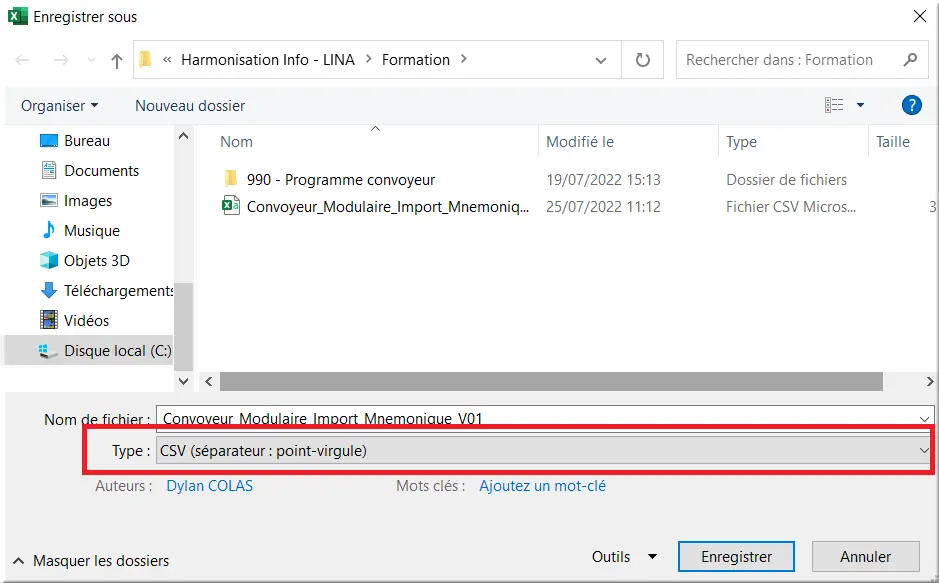
Figure 37 : Enregistrement au format CSV
- Clic menu "Enregistrer sous" ;
- Nom de fichier : Convoyeur-Modulaire-Import-Mnemonique_V01 ⟏ ;
- Type : CSV (Séparateur : point-virgule) ⟏ ;
- Clic Enregistrer.
Exemple de fichier CSV :
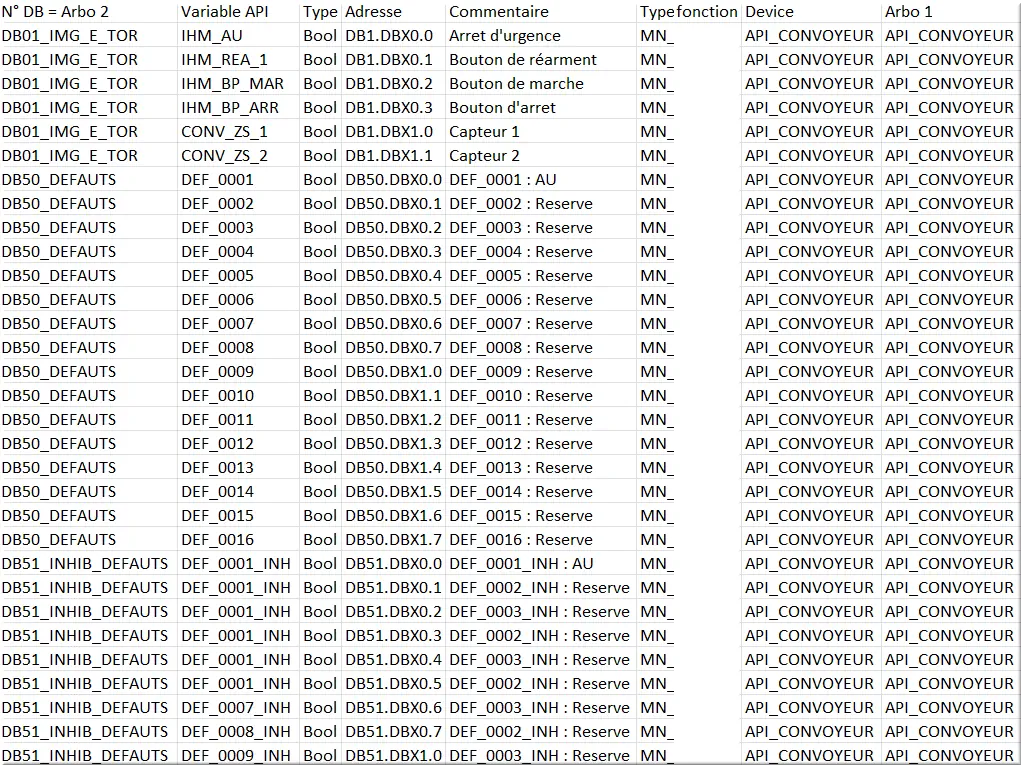
Figure 38 : Exemple de fichier CSV pour intégration
Le même fichier texte .csv ouvert dans Notepad++ donne :
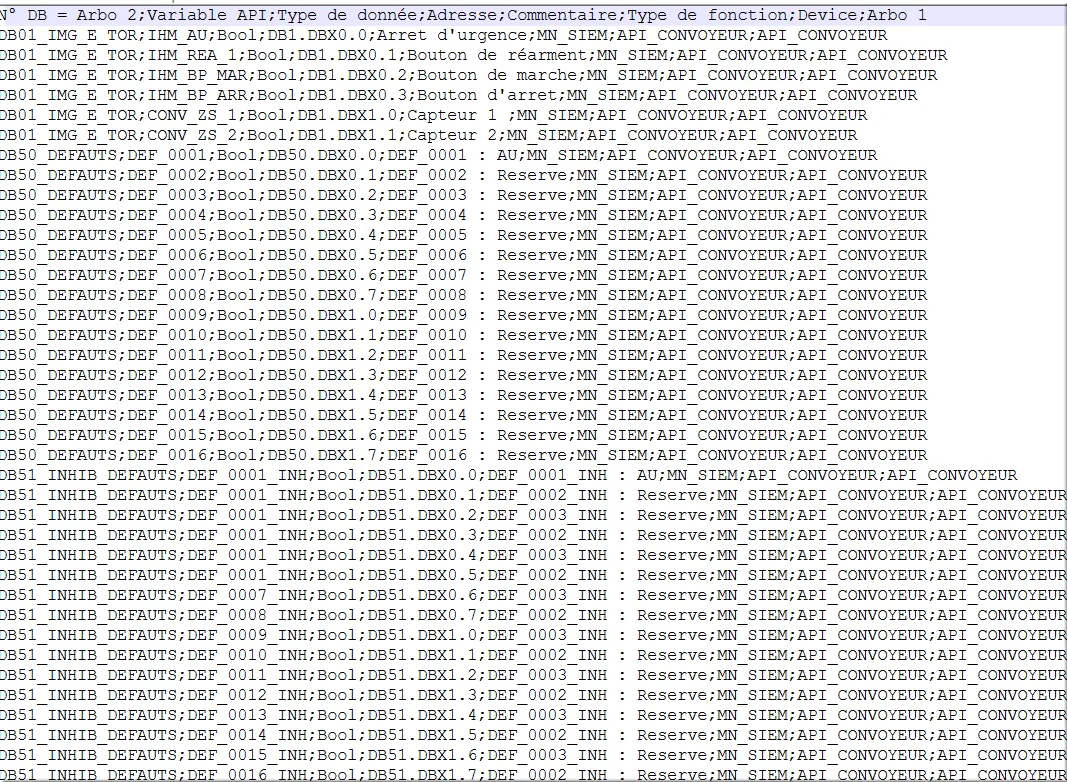
Figure 39 : Exemple CSV brut sous Notepad++
Le fichier CSV est maintenant prêt à l’importation.
Accéder à Référentiel > Devices/Mnémonique > Importer des déclarations :

Figure 40 : Accès Importer des déclarations
Le séparateur de données à l’intérieur du fichier Excel sépare chaque donnée par le caractère ";" point-virgule au lieu de la virgule du format Comma Separated Value: CSV d'Excel.
Sa prise en compte ainsi que le nombre de Ligne de titre sont ajustables en haut à gauche sous Menu principal "Importer des données à partir d'un fichier " sous-entendu CSV :
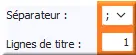
Figure 41 : Configuration du fichier CSV
- Séparateur : ";"
Le symbole "⌄" est la flèche vers le bas de la listbox ⟏ de sélection du séparateur "," ou ";" ; - Lignes de titre : 1. Indique le nombre de ligne de l'entête du fichier Excel au format CSV.
Ouvrir votre fichier CSV précédemment enregistré.
Dans Importer des déclarations à partir d'un fichier :
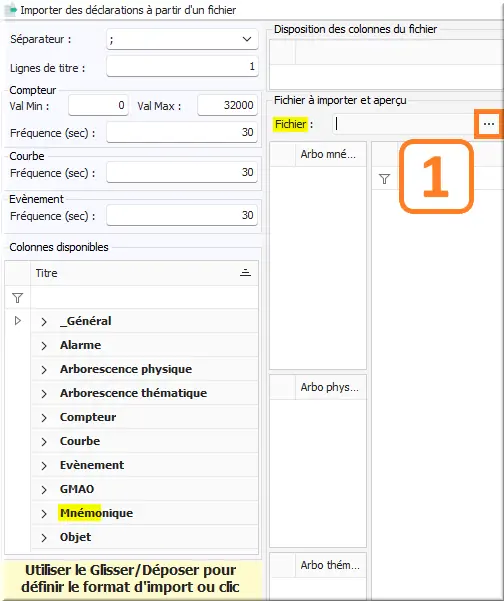
Figure 42 : Choix fichier CSV à importer
- Clic "…" à la droite du champ "Fichier : ".
L’importation se poursuit en caractérisant les différentes colonnes importées. Pour cela, disposer les intitulés de colonnes propres à LINA de sorte à les faire correspondre avec les titres originaux des colonnes du fichier CSV importé. Changer la disposition des colonnes LINA, qui se modifie avec la souris en cliquant-déposant depuis l’arborescence Colonnes disponibles dans l'arbre de gauche Mnémonique.
Pour ajouter une colonne :

Figure 43 : colonne Arbo mnemo niveau 2
- À gauche, sélectionner la colonne Arbo mnemo niveau 2 depuis la liste Colonnes disponibles ;
- Glisser-déposer la dans l’encadré Disposition des colonnes du fichier à droite.
Pour retirer une colonne, effectuer la procédure inverse en la glissant-déposant dans la liste Colonnes disponibles depuis l’encadré Disposition des colonnes du fichier.
Organisez vos colonnes pour les faire correspondre à l’ordre de celles du fichier CSV importé.
⚠ Attention, une colonne dont les données ne sont pas utiles à exploiter doit être affectée à la valeur de colonne Non utilisé.
Si en colonne de gauche, l’aperçu des mnémoniques à importer présente l'anomalie ⮾ ou ⮾ :
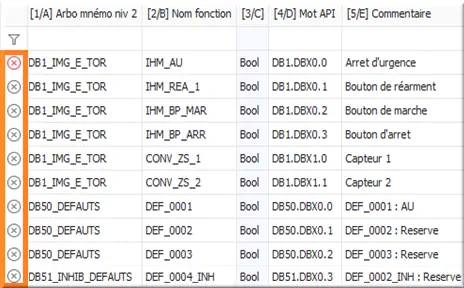
Figure 44 : importation en anomalie
- Laisser le pointeur de la souris sur un des symboles en erreur permet d’obtenir plus d’informations sur le problème causant ladite erreur.
L’analyse avant intégration est dynamique : tant que l’ensemble des mnémoniques importés est marqué comme erroné, c’est que le paramétrage des colonnes est incorrect.

Figure 45 : Icônes d’erreur et message d’erreur
Dans la colonne de gauche de l’aperçu des mnémoniques à importer, un tel paramétrage se caractérisera par :
- Une croix ⮾ qui deviendra rouge lorsqu'elle est survolée par le curseur de la souris.
- La croix ⮾ grise sur fond blanc est une invite pour que l'on résout le problème.
Une fois les colonnes correctement organisées et les potentielles erreurs réglées, on obtient le modèle de configuration pour l’intégration de notre fichier CSV.
À gauche de la liste des mnémoniques, consulter l’arborescence qui sera créée :
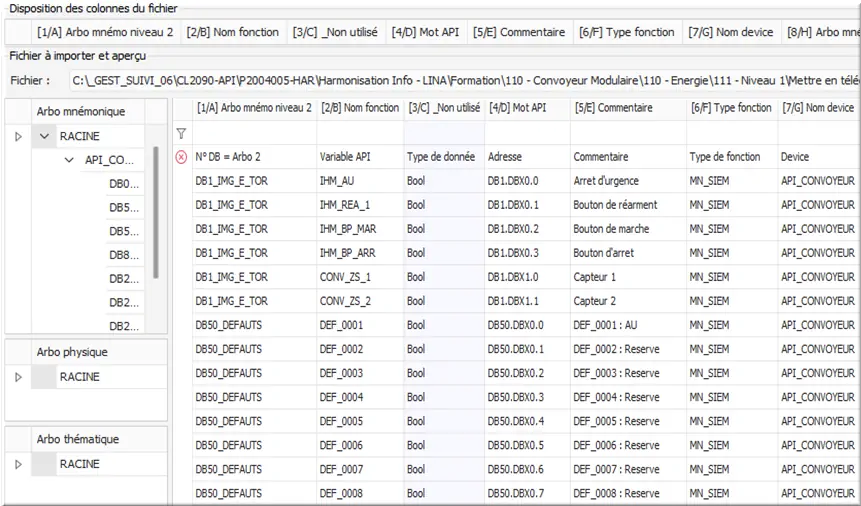
Figure 46 : Modèle de configuration
Si des lignes ⮾ indiquées comme erronées comme la 1ère dénommée "N° DB=arbo 2" restent apparentes, c'est qu'il s’agit des mnémoniques déjà saisis manuellement auparavant.
- Il est possible de sauvegarder le modèle d’importation personnalisé ainsi créé :
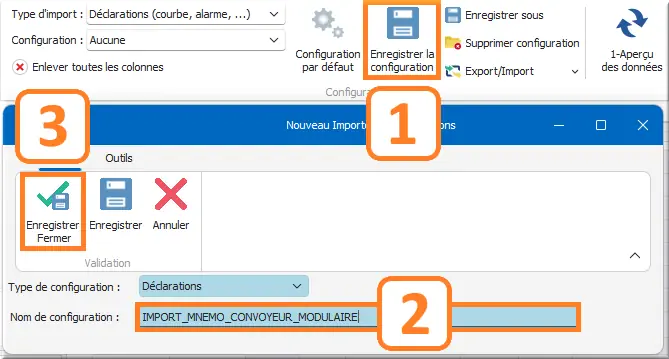
Figure 47 : Sauvegarde du format d'importation
Une fois cette sauvegarde terminée, lancer l’importation des données :
- Clic Importer les données.
Une fenêtre s’ouvre ensuite, résumant l’importation des données et détaillant les potentielles erreurs :
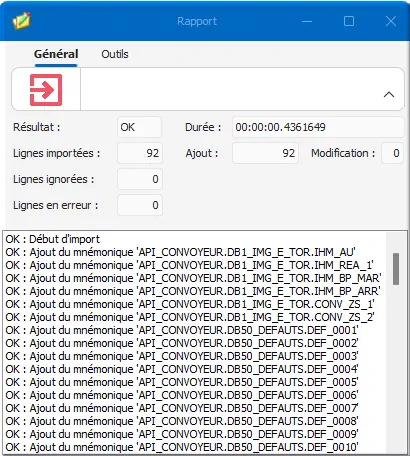
Figure 48 : Rapport d’importation des données
On retrouve le résultat dans le menu Mnémonique.
Dans Arborescence mnémonique :
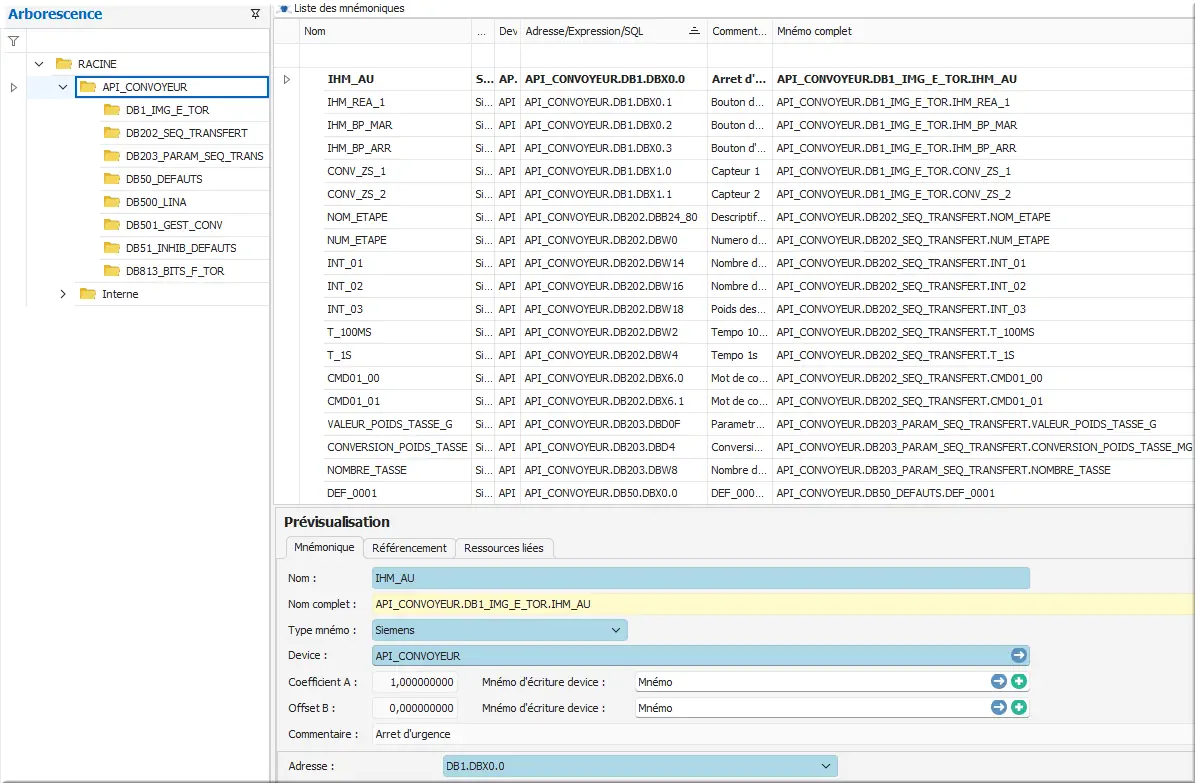
Figure 49 : Résultat importation des mnémoniques
- Clic RACINE > API_CONVOYEUR.
Dans Liste des mnémoniques, tous les mnémoniques ont bien été importés et rangés dans leurs dossiers respectifs avec succès.
En dehors des sauvegardes d’imports personnalisés, il existe des formats par défaut dans LINA.
Retourner dans le menu Importer des déclarations :
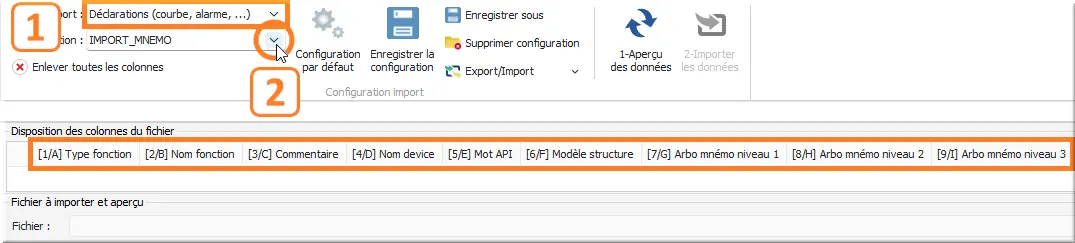
Figure 50 : Exemple configuration d'importation
- Type d’import : Déclarations (courbe, alarme, …) ⟏ ;
- Configuration : IMPORT_MNEMO ⟏.
Automatiquement une disposition des colonnes par défaut vous est proposée.
- Ces formats sont importables et exportables dans LINA par des fichiers ZIP.
Il existe des fichiers modèles pour importer des mnémoniques.
Figure 51 : Fichiers configurations modèles